
答 AI 的 6000 亿美元问题:LLM 应用会如何崛起?
答 AI 的 6000 亿美元问题:LLM 应用会如何崛起?预计在 2025 年能看到企业端 GenAI 的大规模放量
来自主题: AI资讯
8594 点击 2024-08-15 09:58
 搜索
搜索
预计在 2025 年能看到企业端 GenAI 的大规模放量

大语言模型 (LLM) 经历了重大的演变,最近,我们也目睹了多模态大语言模型 (MLLM) 的蓬勃发展,它们表现出令人惊讶的多模态能力。 特别是,GPT-4o 的出现显著推动了 MLLM 领域的发展。然而,与这些模型相对应的开源模型却明显不足。开源社区迫切需要进一步促进该领域的发展,这一点怎么强调也不为过。
随着大型语言模型(LLM)技术日渐成熟,各行各业加快了 LLM 应用落地的步伐。为了改进 LLM 的实际应用效果,业界做出了诸多努力。

大型语言模型(LLM)展现出了令人印象深刻的智能水平。因此,确保其安全性显得至关重要。已有研究提出了各种策略,以使 LLM 与人类伦理道德对齐。然而,当前的先进模型例如 GPT-4 和 LLaMA3-70b-Instruct 仍然容易受到越狱攻击,并被用于恶意用途。
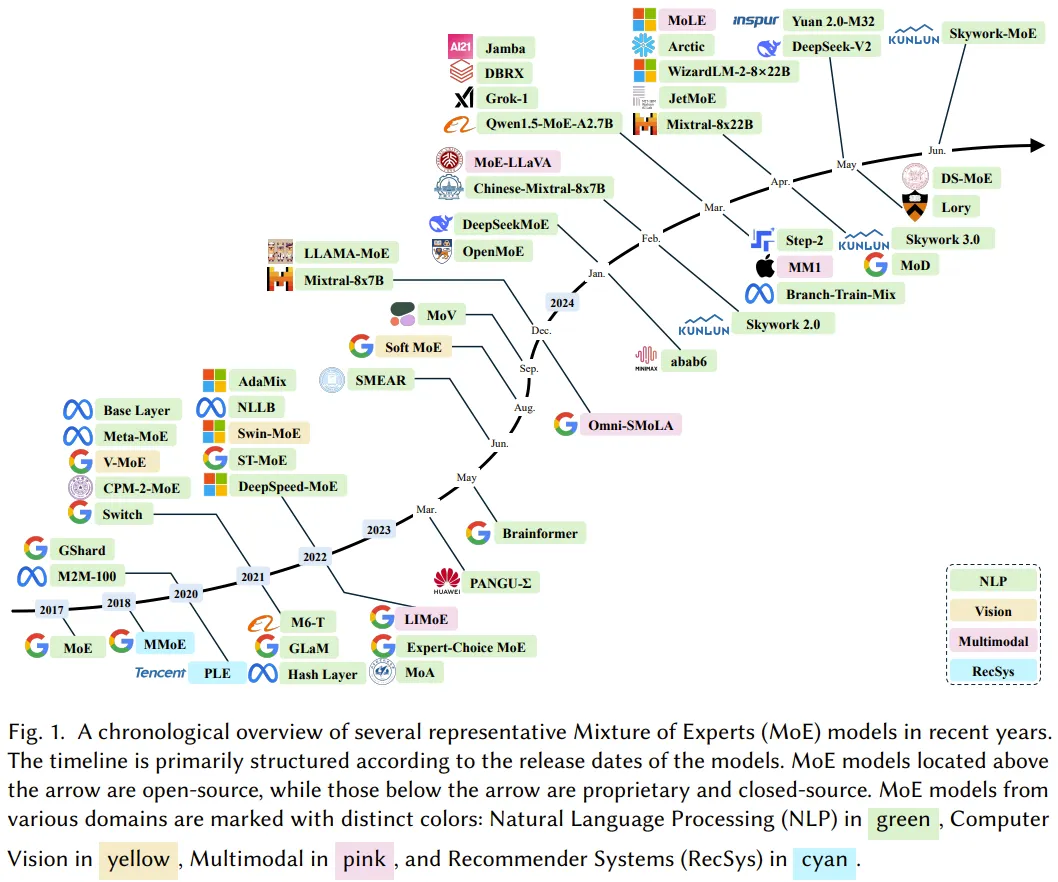
LLM 很强,而为了实现 LLM 的可持续扩展,有必要找到并实现能提升其效率的方法,混合专家(MoE)就是这类方法的一大重要成员。
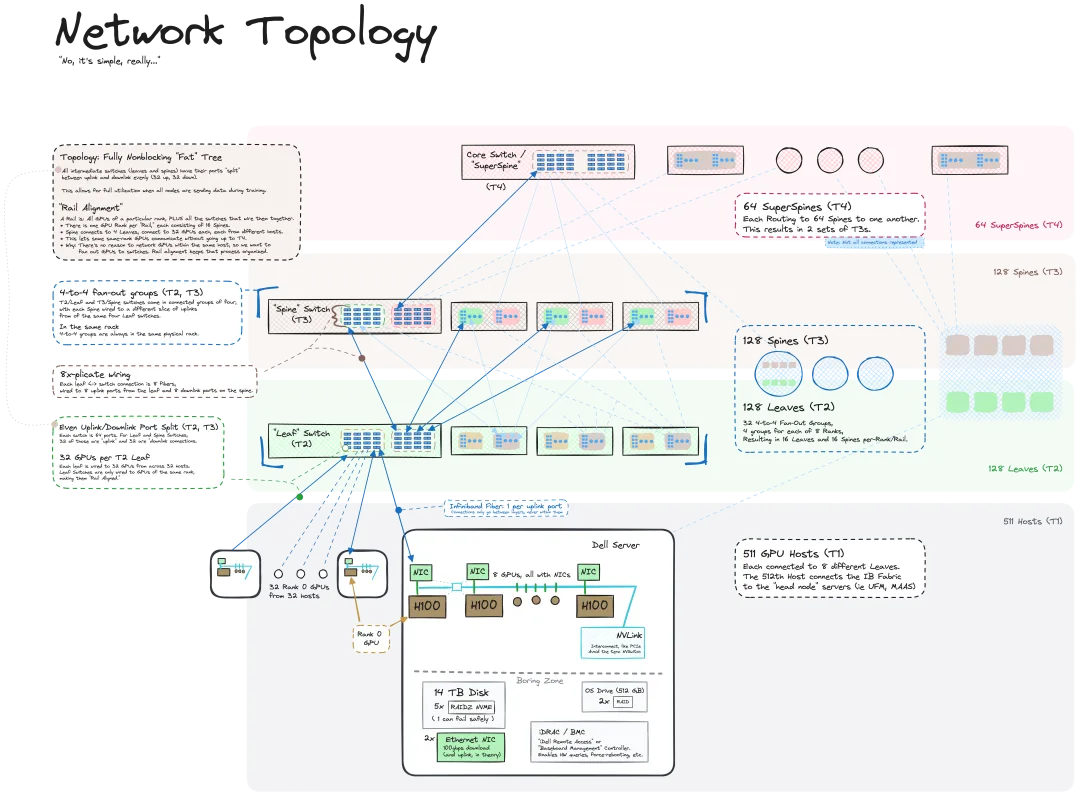
我们知道 LLM 是在大规模计算机集群上使用海量数据训练得到的,机器之心曾介绍过不少用于辅助和改进 LLM 训练流程的方法和技术。而今天,我们要分享的是一篇深入技术底层的文章,介绍如何将一堆连操作系统也没有的「裸机」变成用于训练 LLM 的计算机集群。
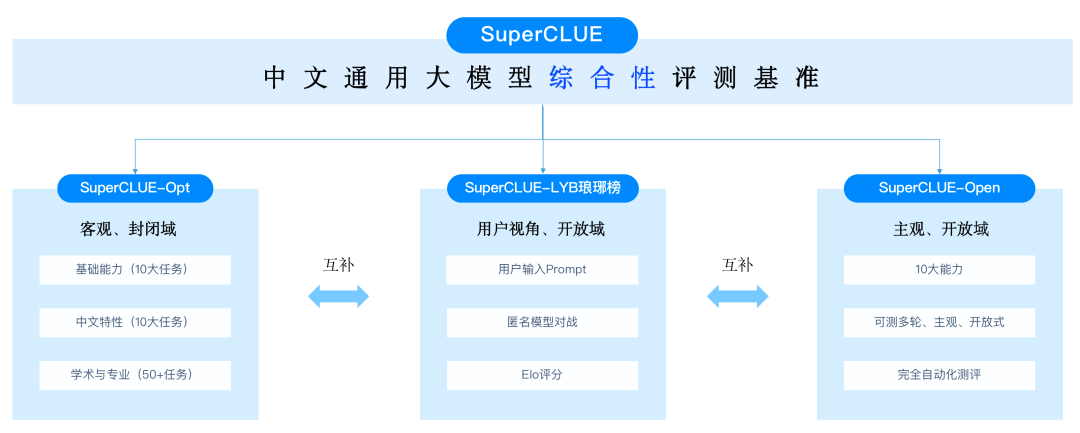
基于评测维度,考虑到各评测集关注的评测维度,可以将其划分为通用评测基准和具体评测基准。
![使用视觉语言模型进行 PDF 检索 [译]](https://blog.vespa.ai/assets/2024-07-15-retrieval-with-vision-language-models-colpali/GRuDx-xXAAAFqBR.jpeg)
近年来,随着大语言模型 (LLM) 的发展,构建检索增强生成 (RAG) 解决方案成为了一个热门话题。RAG 将 LLM 的强大功能与检索模型结合,应用于专有知识数据库。然而,对于开发人员来说,一个主要挑战是将各种文档格式(如 PDF、HTML 等)转换为可供文本模型处理的格式。
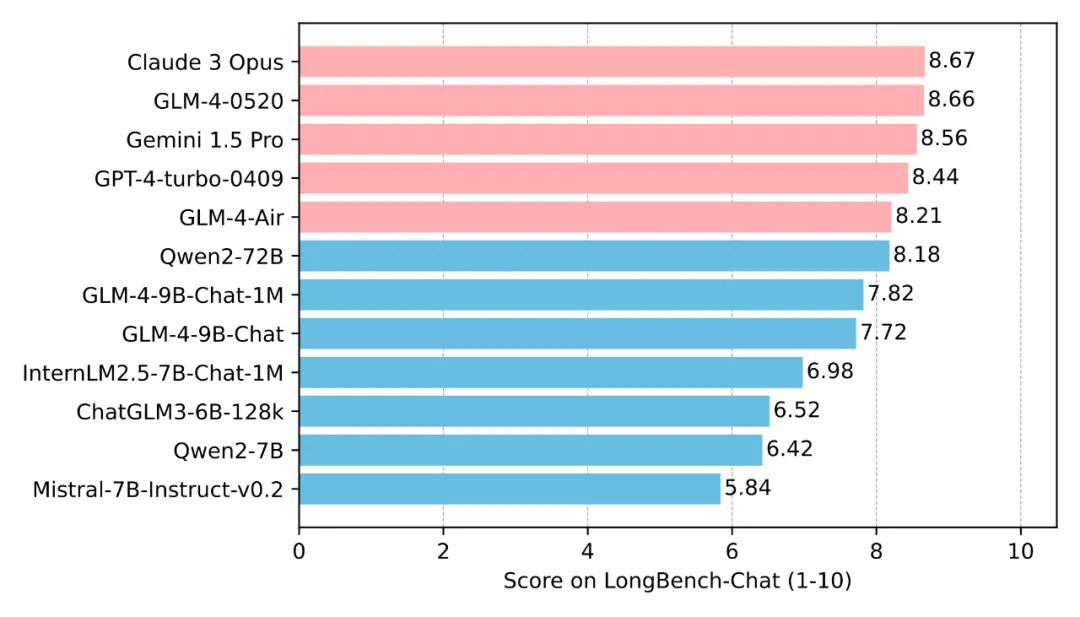
在2023年初,即便是当时最先进的GPT-3.5,其上下文长度也仅限于2k。然而,时至今日,1M的上下文长度已经成为衡量模型技术先进性的重要标志之一。

具身智能是过去一年中和 LLM 一样受到市场高度关注的领域,通用机器人领域什么时候会出现「iPhone 时刻」?这是所有人都关注的问题。拾象团队在过去一年中也深度追踪通用机器人和机器人 foundation model 的进展。本篇文章是我们对机器人领域研究的开源。